開張大吉「智能云」 簽單攜程與AI實(shí)力上位的新風(fēng)向

某科技巨頭旗下「智能云」業(yè)務(wù)高調(diào)宣布與在線旅游巨頭攜程達(dá)成深度合作,標(biāo)志著其正式在數(shù)字技術(shù)服務(wù)領(lǐng)域開張大吉。這一簽約不僅是一筆商業(yè)訂單,更被視為一場AI技術(shù)實(shí)力上位、重塑產(chǎn)業(yè)格局的新風(fēng)向標(biāo),揭示了數(shù)字技術(shù)服務(wù)正邁向以智能為核心的新階段。
此次合作,「智能云」將為攜程提供從云計(jì)算基礎(chǔ)設(shè)施到人工智能解決方案的全棧服務(wù)。重點(diǎn)包括利用AI算法優(yōu)化旅游產(chǎn)品推薦、通過智能客服提升用戶體驗(yàn)、借助大數(shù)據(jù)分析實(shí)現(xiàn)動(dòng)態(tài)定價(jià)與資源調(diào)度等。這不僅是技術(shù)輸出,更是將AI深度融入傳統(tǒng)旅游行業(yè)的毛細(xì)血管,推動(dòng)其向智能化、個(gè)性化轉(zhuǎn)型升級(jí)。
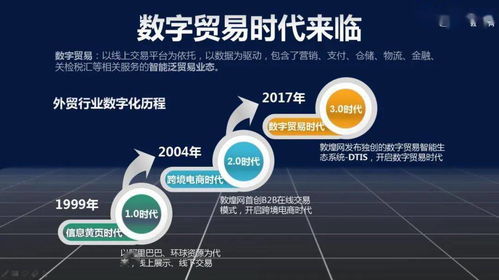
這一事件背后,折射出數(shù)字技術(shù)服務(wù)市場的深刻變革。過去,云服務(wù)競爭多聚焦于算力、存儲(chǔ)等基礎(chǔ)資源;如今,AI能力已成為衡量云服務(wù)商競爭力的關(guān)鍵標(biāo)尺。「智能云」憑借其在機(jī)器學(xué)習(xí)、自然語言處理、計(jì)算機(jī)視覺等領(lǐng)域的長期積累,正將AI從“附加項(xiàng)”變?yōu)椤昂诵囊妗保瑤椭駭y程這樣的行業(yè)領(lǐng)導(dǎo)者構(gòu)建護(hù)城河。
簽單攜程也具有強(qiáng)烈的行業(yè)示范效應(yīng)。旅游行業(yè)鏈條長、數(shù)據(jù)豐富、場景復(fù)雜,是驗(yàn)證AI實(shí)用性的絕佳試驗(yàn)場。成功落地后,其解決方案可快速復(fù)制到金融、零售、制造等領(lǐng)域,加速AI技術(shù)的普惠化進(jìn)程。這預(yù)示著,未來數(shù)字技術(shù)服務(wù)將更側(cè)重于“技術(shù)+場景”的深度融合,而非單純的技術(shù)供給。
新風(fēng)向已明:AI正從技術(shù)概念蛻變?yōu)樯虡I(yè)基礎(chǔ)設(shè)施。對(duì)于「智能云」而言,開張大吉僅是起點(diǎn)。在激烈的市場競爭中,持續(xù)創(chuàng)新、生態(tài)共建與安全可靠將是其贏得未來的基石。對(duì)于千行百業(yè),擁抱此類智能化的數(shù)字技術(shù)服務(wù),或?qū)⒊蔀閿?shù)字化轉(zhuǎn)型中決勝的關(guān)鍵一步。
如若轉(zhuǎn)載,請注明出處:http://m.ah163.com.cn/product/48.html
更新時(shí)間:2026-06-09 08:45:43